
I am an assistant professor of late imperial Chinese literature and interdisciplinary data science at Princeton University, where I am also the associate faculty director of the Center for Digital Humanities. I have held faculty positions in Chinese Studies at William & Mary and in Digital Humanities at Leiden University (where I also helped establish the Leiden University Centre for Digital Humanities).
My research exists at the intersection of Chinese literary studies, print history, computational analysis, machine learning, artificial intelligence, and the digital humanities. My first monograph project, tentatively titled Quasi-history and the Borders of Fiction: Digital Explorations of the Frontiers of Late Imperial Chinese Historical Narratives, is currently in review and is a quantitative analysis of the complex relationship between fictional and historical narrative in Ming and Qing China. In my second monograph project, tentatively titled The Vectorized Jinpingmei, I computationally analyze source material, authorship, philosophical influence, and more in the late Ming novel Plum in the Golden Vase.
My research also deals extensively with quantitative/computational methods. Among other things, I am studying the influence of training corpora on bespoke language models designed to analyze premodern Chinese materials. Additionally, in collaboration with Tina Lu, I am building pipelines using VLMs to leverage large image collections to study the reuse of woodblocks in late imperial China.
I archive my research as presented in papers and talks on this page. You can find information on my teaching (which includes the visualizations/animations I am designing for pedagogical purposes) and other activities using the nav bar at the top.
Machine learning as a tool for Chinese literary Scholarship
September 2022: Pacific Neighborhood Consortium Conference, University of Arizona
crosslinguistic semantic textual similarity of buddhist chinese and classical tibetan (journal Article)
Forthcoming in the Journal of Open Humanities Data, co-authored with equal contributions from Rafal Felbur and Marieke Meelen. More information will be updated here when the article appears.
digital approaches to Plum in the Golden Vase (book chapter)
July 2022: In Approaches to Teaching in the Plum in the Golden Vase, edited by Andrew Schonenbaum. Published by Modern Language Association.
Machine-aided Detection of the sources of jinpingmei
June 2022: European Chinese Digital Humanities Conference, Aix-Marsielle University
machine learning models for literary Chinese text corpora
May 2022: Advanced Methods in Digital Korean Studies Conference, Seoul National University
experiments in ‘reading’ digital corpora
May 2021: The Meaning of Text(s) Zoom Conference, Hong Kong University of Science and Technology
crossing registers: a digital account of heteroglossia in Jinpingmei
March 2021: East Asian Studies Research Seminar, University of Manchester
East Asian Digital Humanities in 2020
December 2020: Animal Crossing: New Digital Humanities Experimental Talk
digital humanities and east asian studies in 2020 (Journal Article)
Fall 2020: History Compass https://doi.org/10.1111/hic3.12628
Abstract: Although East Asian studies scholars have a long history of using technology to their advantage, starting in at least the 1970s, East Asian digital humanities lags behind digital humanities in other parts of the world. This gap is rapidly closing, and a variety of new resources, tools, and communities have developed in the last few years. At the same time, this progress has produced a remarkable flowering of research. This article provides a broad overview of some of the more recent and important trends in East Asian digital humanities. I discuss a variety of important datasets that include text corpora, geographic information, biographic data, images, and more. I also introduce a number of analytical tools, discuss community building efforts, and discuss some of the research that has emerged from this. Finally, I address efforts in digital humanities education, because although East Asian scholars are rapidly adopting digital tools, the field still faces a gap in knowledge driven by a lack of easily accessible training opportunities.
innocent x pamphij’s architectural network in rome (Journal Article)
Fall 2020: Renaissance Quarterly, 73.3. Second author, co-written with Stephanie Leone. https://doi.org/10.1017/rqx.2020.122
Abstract: This study employs network analysis and microhistory to challenge the standard narrative about architecture and patronage in Baroque Rome, that of celebrity patron-artist relationships. It investigates the artists and artisans below this elite team and the plurality of relationships that developed among them. The subject is Innocent X Pamphilj's monumental works of art and architecture, at the Vatican, Piazza Navona, Campidoglio, Lateran, and Janiculum Hill, commissioned for the 1650 Holy Year. It argues that competent artisans and their relationships influenced the operation of building sites and presents Innocent X as the patron of an industrious architectural enterprise.
intertextuality, stylometry, and the flow of historical information in late imperial china
December 2019: Digital Textual Analysis in Traditional Chinese Studies, Australian National University
stylometry, chinese, and following the flow of information
November 2019: Trier University
digital infrastructure, bibliographical data, and chinese print history
November 2019: International Workshop for Professional Librarians, National Central Library, Taiwan
extracting stylistic and intertextual markers from chinese text
March 2019: Digital Scholarship Symposium, Chinese University of Hong Kong
a blast-based language-agnostic text reuse algorithm in markus and sequence alignment optimized for large chinese corpora (Journal article)
March 18, 2019: Journal of Cultural Analytics. First author, co-authored with Mees Gelein https://doi.org/10.22148/16.034
intertextuality, classification, and late imperial chinese literature
February 2019: WordLab, University of Pennsylvania Library
Society, Intertextuality, and the origins of the Plum in the Golden Vase
January 2019: NYU Abu Dhabi
Digital humanities, Chinese studies, and a bit about the Sanguo
December 2018: Princeton University (Remote presentation)
Experiments with supervised machine learning models for source detection in late imperial Chinese corpora

Stylistic relationships between 50 character sections of the Yujing xintan (pink) and the Jingshi yinyang meng (blue-green).
November 2018: Seoul National University
In this talk I further demonstrated the results of my recent efforts to computationally identify quote sources in late imperial Chinese literature. In this slide from the talk, you can see the stylistic relationships among 1000 fifty-character sections of text taken at random from the Yujing xintan (玉鏡新譚) and the Jingshi yinyang meng (警世陰陽夢). These two important texts about Wei Zhongxian (魏忠賢) were published in 1628 and provide an interesting test case for computational source identification. The style of these two works is fairly distinct, with only some overlap in the middle. It is possible to build a machine learning model that distinguishes the origin of these sections with around 98 percent accuracy.
Where did all these rumors come from? Computationally Identifying Intertextuality and Machine-Classifying Its Source in a Late Imperial Chinese Corpus
Talk and Workshop poster
October 2018: University of Virginia
From the abstract: “Authors of late imperial Chinese quasi-historical documents recycled text with little regard for specifying their sources or maintaining fidelity to them. Identifying these instances of intertextuality provides a valuable window into how historical information transformed as it propagated through texts. Yet the mechanics of this transmission can be difficult to assess because of textual attrition and often limited publication information for extant documents. As such, it is often unclear which document is quoting which. In this talk, Paul Vierthaler will briefly introduce a method for extracting these ubiquitous instances of intertextuality and describe his current research in applying machine learning algorithms to predict the text of origin for any given quote.”
Reading Late Imperial Corpora: Or, Why I Care about Bibliographic Data

Detail from a network of texts that mention Wei Zhongxian.
August 2018, Brown University
In this talk I presented on my current development of an extensive bibliographic graph database (currently using neo4j) focused on premodern Chinese works. Since completing work on my intertextuality detection algorithms, I have now begun searching for ways to detect which (if any) text in my corpus originally contained the shared material. As such, the primary purpose behind building this database is to refine the machine learning models I am developing to help me track information movement through Chinese corpora.
In this image (a detail from one of the slides in the talk), you can see a network of texts. These are all works that mention the eunuch Wei Zhongxian (魏忠賢) and the lines represent how many characters of text the documents share with each other. The database (and machine learning models) will help me add directionality to this network.

PCA and Network Analysis Explorer
I presented a version of this visualization at the DHAsia summit in late April 2018. In it, I display a principal component and network analysis of nearly 18k chapters or juan from historical and fictional genres of texts written in the Ming and Qing dynasties. The PCA is based on the relative frequencies of the 1k most common characters in the corpus.
The primary difficulty with principal component analysis as a method for studying Chinese corpora is identifying how individual text fit within the larger picture. This visualization is meant to facilitate moving from the macro-level analyses like the ones seen in my 2016 Cultural Analytics paper to the macro level where individual documents are identifiable.
I will continue to refine this, and if there is interest in the community, I may release it so others can use it for their own data.
Digital Humanities and Text Mining: Stylistic and Intertextual Analysis of Large Corpora

May 2018, Utrecht University
At Utrecht, I discussed the methodological approaches I take in my research on late Imperial Chinese literature, specifically aimed at an audience of data scientists. From the abstract: "Paul studies the relationships among historical and fictional documents written in late Ming and early Qing China (1550 to 1700) at the corpus level. To do this, he uses a variety of methods developed by linguists, computer scientists, and biologists. In his talk, Paul will cover stylometric analysis and an intertextuality detection algorithm based on the bioinformatics algorithm BLAST (Basic Local Alignment Search Tool). While this talk will ground the methodology in specific research questions, he will mainly focus on describing his approach to blending information retrieval with literary studies."
Sequence Alignment and Intertextuality Detection in Large Chinese Corpora

April 2018, Stanford University
The Digital Humanities Asia Summit will be held in April of 2018, a continuation of the very successful DHAsia series that began in February 2016. I will be discussing the utility of sequence alignment for comparing and closely reading carefully digitized manuscript editions of imperial Chinese texts. I will also discuss my continued research into intertextuality in large Chinese corpora.
Computational Analysis of Intertextuality and Stylistic Relationships in Late Ming and Qing Dynasty Fiction
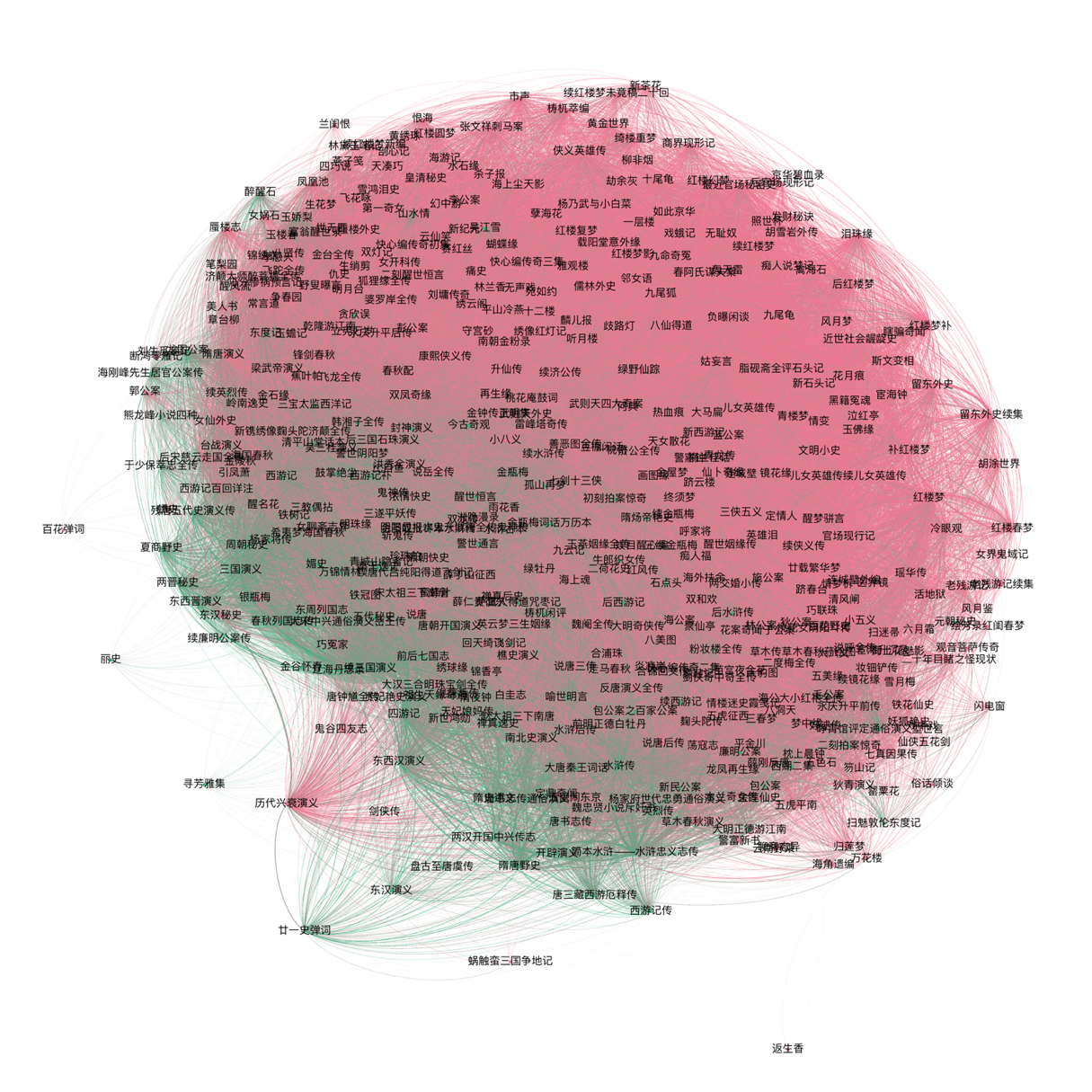
Network of shared language in Ming (green) and Qing (pink) Dynasty Fictional texts.
October 19th, 2017, Johns Hopkins University
In this talk, I discussed the use of digital methods to study and analyze stylistic and intertextual relationships among novels and short stories written during the late Ming and Qing Dynasties. There is a long tradition of borrowing prose from earlier works in imperial China; the adaptation of large sections of the Water Margin into the Plum in the Golden Vase being a famous example. These borrowings are now accessible to computational inquiry due to the creation of digital corpora of late Imperial Chinese documents. I described my recent research and discussed my use of a method for tracing text reuse across a digital Chinese corpus (based on the bioinformatics BLAST algorithm), and a method to study stylistic similarity. I then discussed what such methods can tell us about fiction written during the Qing dynasty.
If you would like to read the associated paper, which describes this new branch of my research, please feel free to contact me.
Working with Imperial Chinese Corpora: Studying Document Similarity and Text Reuse

Percent of each chapter found in a text written prior to the initial circulation of the Plum in the Golden Vase, which began in the late 1500s.
July 11th, 2017, Leipzig University
In this talk, presented at the Global Philology: Big Textual Data workshop, I discussed how to identify text reuse in Chinese corpora. My primary focus was on identifying approaches that will allow scholars to text reuse at the scale of tens of thousands of documents (i.e. corpora containing hundreds of millions to billions of Chinese characters). I also briefly discussed an application of this process, showing how we can use such computational methods to identify how works like the Plum in the Golden Vase appropriated text from earlier documents (a computational extension of the manual work done by scholars like Patrick Hanan in the Sources of the Chin P'ing Mei).
Analyzing Printing Trends in Late Imperial China Using Large Bibliometric Datasets
Harvard Journal of Asiatic Studies, Issue 76
This article, based on my work using online library catalog records to study trends in late Imperial printing, appears in the June 2016 issue of the Harvard Journal of Asiatic Studies. Printing of the Journal had been delayed, but as of April 23rd, 2017, the article can be accessed on project MUSE. You will likely need an institutional subscription to view the article.
Abstract: Online library catalog records of Chinese texts written during the late imperial period contain a wealth of traditional bibliographic information. Nearly 35,000 records on texts written from 1550 to 1799, available through WorldCat, describe these works in minute detail: the size of a page's text frame, the number of characters per page, print quality, genre, and so on. Aggregating this bibliographic information allows for a rapid and statistically rigorous approach to quantitative print history. Diachronic analysis of the size of the text frame of the late imperial texts represented by these records reveals a rapid increase in the production of very small format texts during the latter part of the eighteenth century. When integrated with information on genre, this analysis confirms Robert Hegel's hypothesis that novels were printed in ever smaller formats during the Qing dynasty and traces the origin of this trend to the 1750s.

Talk poster
Digital Approaches to Intertextuality and Stylistics in the Plum in the Golden Vase
February 24th, 2017, Arizona State University
Extensive digitization efforts are creating large corpora of imperial Chinese texts, a process that is opening a variety of new avenues for research. Digital corpora are valuable not just for democratizing access to materials, they are also creating the possibility for computational approaches to Chinese literature. Text-mining, and other digital techniques, are beginning to allow scholars to use these materials to study Chinese literature at a large systematic level. In this talk, I will discuss my current research into using these large digital corpora to identify and stylistically analyze the wide variety of textual materials that are reproduced within the late Ming novel the Jin Ping Mei 金瓶梅 The Plum in the Golden Vase. It is an illuminating case, as it is well known for its highly intertextual and experimental nature, making large scale digital analysis a fruitful exercise. This analysis can situate the Plum in the Golden Vase within the broader stylistic context of its source materials. I begin by identifying where the anonymous author of the novel relies on language that originates in earlier works. Then, I analyze the relationships among these source works using stylometric analysis, a type of analysis that has proven useful for both authorship attribution and genre studies. This allows me to visualize the relationships among the Plum and the Golden Vase, its sources, and its later editions in ways that were not possible in a pre-digital world. The goal of this research is to distill the original voice of the author to facilitate the larger task of determining his or her identity. As part of this talk, I will also discuss some of the pitfalls inherent in digital research on imperial Chinese texts.

t-SNE comparing document vectors representing works of fiction, historical fiction, unofficial histories, and official histories.
Clustering Late Imperial Chinese Texts by Style: Principal Component Analysis and t-SNE.
July 10, 2016, Leiden University
As large corpora of late Imperial Chinese texts become more readily available, they open up exciting new possibilities for digital research. They offer an opportunity to grasp large stylistic trends that are invisible at narrower levels of analysis. However, their number and highly variable content introduce computational and visualization difficulties. Fortunately, a variety of linear algebraic and machine-learning algorithms exist that facilitate these tasks. In this talk, I will compare and contrast several of these algorithms in the context of late Imperial Chinese literature. In the first part of the talk, I will discuss using the benefits and drawbacks of using PCA (Principal Component Analysis), a type of linear algebraic transformation of document-term matrixes, to analyze a variety of historical and semi-historical texts. In the second portion, I will focus on analyzing these same documents with a related machine-learning technique called t-SNE (t-distributed Stochastic Neighbor Embedding). This technique may offer significant advantages over older clustering methodologies, while producing easy to understand, meaningful visualizations. I will finish by discussing the insights these algorithms offer into the nature of late Imperial stylistics.

PCA comparing various quasi-historical late Imperial Chinese documents
Fiction and History: Polarity and Stylistic Gradience in Late Imperial Chinese Literature
Appears in CA: Journal of Cultural Analytics. Published May 23, 2016.
In this article I use stylometric analysis to evaluate the stylistic relationships among a collection of "quasi-historical" documents dating from the late Imperial period in China (the works were mostly written from 1550 to 1800). I argue that when I use principal component analysis and hierarchical cluster analysis to analyze a large corpus of Chinese texts that contain historical narratives, I find a gradient of style that runs from purely fictional works through historical romances (novels with historical content) and yeshi 野史 unofficial histories to official historical works vetted by the imperial government.

Principal Component Analysis of the Chapters of the cihua edition of the Plum and the Golden Vase.
Who Wrote the Jin Ping Mei? Stylometry and Machine Learning for Chinese Studies.
April 2016, Digital Approaches to Chinese Culture, Part 1: Tools and Methods for Textual and Historical Analysis. Association for Asian Studies Conference, Seattle, WA.
Stylometric analysis, which operates on the premise that authors leave a distinct signature in their writing that can be statistically identified, is an important branch of authorship attribution research. It has proven useful in a number of applications, from confirming James Madison as the author of several disputed Federalist Papers to identifying J.K. Rowling as the author of a pseudonymous mystery novel. As researchers in Chinese studies gain access to an increasing number of digital editions of classical and vernacular Chinese texts, stylometric tools are becoming useful for conducting authorship attribution research and comparative stylistic analysis. In this paper, I introduce several new digital tools (stylometric analysis and machine-learning algorithms) that allow me to explore the probable authorship of the late Ming dynasty novel the Jin Ping Mei金瓶梅 (Plum in the Golden Vase). Written pseudonymously by the Lanling xiaoxiao sheng 蘭陵笑笑生 (Laughing Scholar of Lanling), the authorship of this work has been argued over since it first began circulating in manuscript form in the late sixteenth century. A wide variety of probable authors have been suggested, many of whom left behind works that have recently been digitized. I propose a new line of analysis that significantly narrows the range of possible candidates by comparing character usage frequency in the Jin Ping Mei with contemporary texts of known authorship. A machine-learning algorithm then classifies the texts by probable author, determining which works have the most similar character frequencies.
The focus of this talk was primarily methodological (the talks at Stanford and Peking University were more focused on results).

Wang Shizhen and his proximal social network. Created with China Biographical Database data and Gephi.
Digital Research into the Authorship of the Jin Ping Mei
February 9, 2016, Stanford University
In this talk Paul Vierthaler will share his research into using computer-aided authorship detection methodologies to offer insight into the authorship of the late Ming novel the Jin Ping Mei 金瓶梅 (Plum in the Golden Vase). Pseudonymously written by the “Laughing Scholar of Lanling” sometime in the late 1500s or early 1600s, the identity of the Plum in the Golden Vase’s author has been the subject of intense debate since its initial circulation. Many candidates have been proposed, argued over, and discarded, but scholars continue to offer new possibilities and to rehash old arguments. Paul offers new insight into the authorship question using two distinct lines of evidence derived from network and stylometric analysis. Scholars currently have a relatively clear, but possibly incomplete, picture of who possessed a Plum in the Golden Vase manuscript prior to the cihua edition’s 1617 publication. From this end-point, modeling manuscript circulation in elite social networks offers some evidence for the work’s initial starting point. Stylometric analysis offers further evidence: by analyzing n-gram frequency in a variety of contemporary texts, and using machine learning based classification algorithms, the author’s identity becomes clearer.
Digital Analysis and the Authorship of the Jin Ping Mei (in Chinese)
January 9, 2016, Peking University
In this talk, Paul Vierthaler will discuss using digital methods to analyze anonymous authorship in late Ming and early Qing novels. This talk will focus on using two distinct lines of evidence to assess the potential authorship of the late Ming novel the Jin Ping Mei. In the first part of his talk, Paul will assess the known circulation of manuscripts of the Jin Ping Mei using the China Biographical database and social network analysis. In the second portion of his talk, Paul will discuss the use of stylometric and machine learning analyses in evaluating the most likely candidate author.
数字分析与金瓶梅的作者
2016年1月9日,北京大学
在这次演讲中,李友仁将讨论如何使用数字人文的方法来分析明末清初那些作者不详小说的作者。李友仁会从两个角度来探索金瓶梅的潜在作者:第一,通过中国历代人物传记资料库(China Biographical Database)和社会网络关系分析(Social Network Analysis)来研究金瓶梅抄本的流传。第二,使用 "stylometry" 和机器学习来分析电子化文本,从而评估最有可能的作者。

Textual relationships among a variety of Ming and Qing texts.
Quantitative historical imagination: late Ming and early Qing Chinese unofficial histories, novels, and dramas.
November 20, 2015, University of Chicago
In this talk, Paul Vierthaler will discuss his research in using digital techniques to analyze the differences among texts that transmitted unofficial historical narratives in the late Ming and early Qing periods in China. This talk centers on novels on current events, dramas on current events, and yeshi (unofficial, or wild, histories). These texts, which Paul calls “quasi-histories”, purport to move information about recent events, but their historical validity and generic nature have been debated by contemporary and modern scholars. In the past, their sheer numbers made systematic analysis difficult. Paul will begin with a meta-analysis of extensive secondary bibliographic information to analyze the claim that late Ming and early Qing quasi-histories were unprecedentedly focused on the recent past. He will finish with a discussion on using stylometric analysis to explore the complex stylistic relationships among texts of these genres, and their relationship with official dynastic histories.
Much of the contents of this talk can be found in the "Fiction and History" article.

Hierarchical cluster analysis of the 100 chapters of the Plum and the Golden Vase.
Who wrote the Jin Ping Mei? Early Results of Quantitative Explorations.
January 2015, Princeton University
This was the first talk I gave on my efforts to use the digital humanities to study the author of the Jin Ping Mei. I gave this talk to Paize Keulemans seminar on the Jin Ping Mei at Princeton. It was mostly exploratory analysis and focused on ways of understanding the relationships among the chapters of the novel. I also presented very early authorship analysis results.

Digital Approaches to Late Imperial Chinese Literature: Exploring Quasi-historical Texts.
September 19, 2014. An Wang Postdoctoral Talk, Fairbank Center for Chinese Studies, Harvard University.
The ever-increasing availability of digital information on pre-modern Chinese texts, from online bibliographic records to fully digitized transcripts, is allowing scholars to adapt mathematical and statistical tools for literary analysis. Paul Vierthaler will address the promise and some of the drawbacks of using digital techniques to analyze braod stylistic differences among late imperial Chinese texts. Stylometry, developed by linguists and widely used in authorship attribution studies, shows promise for illustrating differences in style among various genres of late Imperial writing. This, in turn, provides insight into why traditional bibliographers often classified unofficial histories as novels.